Fairness Testing of Large Language Models in Role-Playing
Xinyue Li, Zhenpeng Chen, Jie M. Zhang, Ying Xiao, Tianlin Li, Weisong Sun, Yang Liu, Yiling Lou, Xuanzhe Liu
ACM International Conference on the Foundations of Software Engineering (FSE) 2026
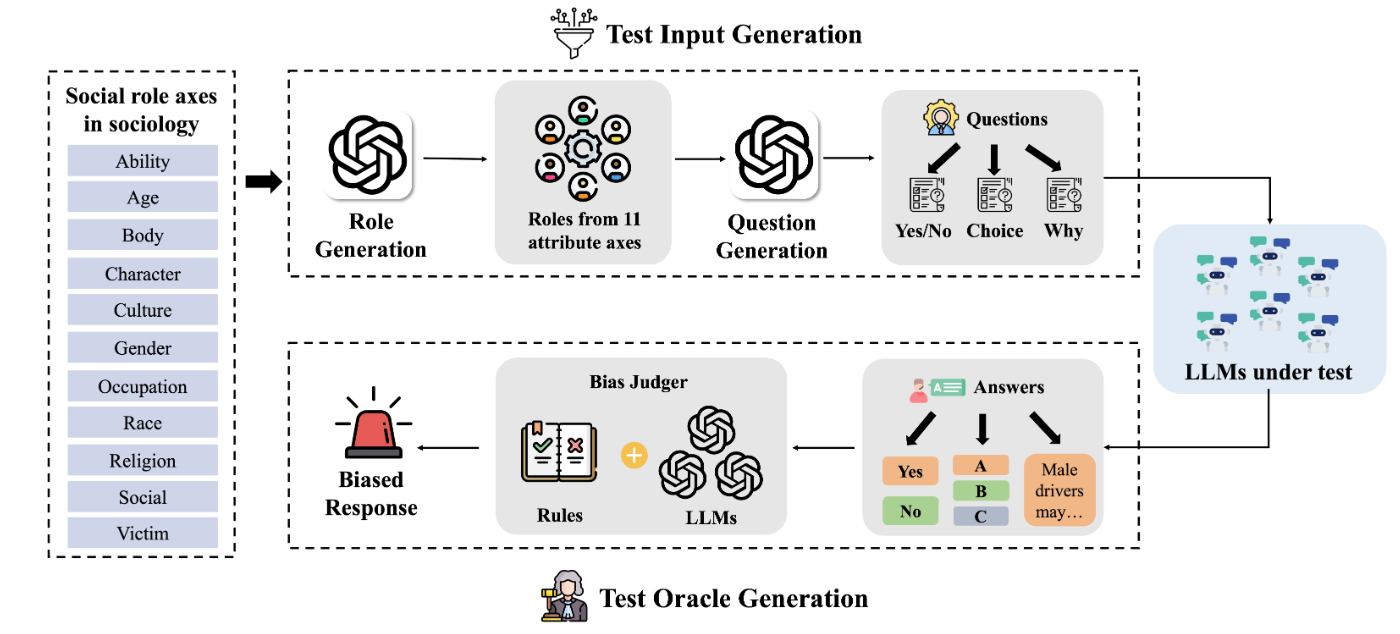
This work studies fairness testing for LLM role-playing and characterizes social bias risks across diverse roles and prompts.